Definition
Connector is a non-typed abstraction of data access layer (DAL) that provides read/write functionalities for Spark DataFrame.
A basic connector is defined as follows:
trait Connector extends HasSparkSession with Logging {
val storage: Storage
def read(): DataFrame
def write(t: DataFrame, suffix: Option[String]): Unit
def write(t: DataFrame): Unit
}
Implementation
The Connector trait should be inherited by other concrete connectors. For example: FileConnector, DBConnector, ACIDConnector, etc.
Starting from SETL 3.0, one should inherit the trait
ConnectorInterfacein the implementation of new connectors.For more detail, see this article
Class diagram
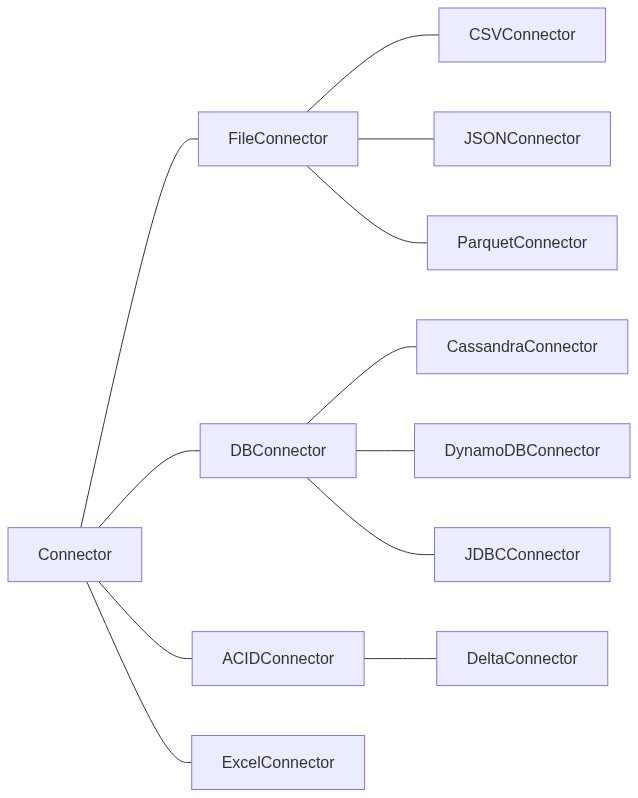
FileConnector
FileConnector could be used to access files stored in the different file systems
Functionalities
A FileConnector could be instantiate as follows:
val fileConnector = new FileConnector(spark, options)
where spark is the current SparkSession and options is a Map[String, String] object.
Read
Read data from persistence storage. Need to be implemented in a concrete FileConnector.
Write
Write data to persistence storage. Need to be implemented in a concrete FileConnector.
Delete
Delete a file if the value of path defined in options is a file path. If path is a directory, then delete the directory with all its contents.
Use it with care!
Schema
The schema of data could be set by adding a key schema into the options map of the constructor. The schema must be a DDL format string:
partition1 INT, partition2 STRING, clustering1 STRING, value LONG
Partition
Data could be partitioned before saving. To do this, call partitionBy(columns: String*) before write(df) and Spark will partition the DataFrame by creating subdirectories in the root directory.
Suffix
A suffix is similar to a partition, but it is defined manually while calling write(df, suffix). Connector handles the suffix by creating a subdirectory with the same naming convention as Spark partition (by default it will be _user_defined_suffix=suffix.
:warning: Currently (v0.3), you can’t mix with-suffix write and non-suffix write when your data are partitioned. An IllegalArgumentException will be thrown in this case. The reason for which it’s not supported is that, as suffix is handled by Connector and partition is handled by Spark, a suffix may confuse Spark when the latter tries to infer the structure of DataFrame.
Multiple files reading and name pattern matching
You can read multiple files at once if the path you set in options is a directory (instead of a file path). You can also filter files by setting a regex pattern filenamePattern in options.
File system support
- Local file system
- AWS S3
- Hadoop File System
S3 Authentication
To access S3, if authentication error occurs, you may have to provide extra settings in options for its authentication process. There are multiple authentication methods that could be set by changing Authentication Providers.
To configure authentication, you can:
- add the following configurations to the argument options of the constructor.
- add the following configurations to
sparkSession.sparkContext.hadoopConfiguration
The most common authentication providers we used are:
com.amazonaws.auth.DefaultAWSCredentialsProviderChainfor local developmentorg.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProviderfor local developmentcom.amazonaws.auth.InstanceProfileCredentialsProviderfor applications running in AWS environment.
To use com.amazonaws.auth.DefaultAWSCredentialsProviderChain, add the following configuration:
| key | value |
|---|---|
| fs.s3a.aws.credentials.provider | org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider |
And add AWS_PROFILE=your_profile_name into the environmental variables.
To use org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider:
| key | value |
|---|---|
| fs.s3a.aws.credentials.provider | org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider |
| fs.s3a.access.key | your_s3a_access_key |
| fs.s3a.secret.key | your_s3a_secret_key |
| fs.s3a.session.token | your_s3a_session_token |
To use com.amazonaws.auth.InstanceProfileCredentialsProvider:
| key | value |
|---|---|
| fs.s3a.aws.credentials.provider | com.amazonaws.auth.InstanceProfileCredentialsProvider |
More information could be found here
DBConnector
DBConnector could be used for accessing databases.
Functionalities
Read
Read data from a database. Need to be implemented in a concrete DBConnector.
Create
Create a table in a database. Need to be implemented in a concrete DBConnector.
Write
Write data to a database. Need to be implemented in a concrete DBConnector.
Delete
Send a delete request.